

Kubernetes is an open-source orchestrator for deploying containerized applications and is used by a growing number of people to deploy reliable distributed systems. The core of Kubernetes is its cluster that enables applications to be defined and deployed with simple declarative syntax.
The cluster provides numerous control algorithms for repairing applications in the case of failure. For successful management of these clusters, we need to configure different levels of attacks ranging from application compromise to denial-of-service.
In the case of active attacks, the cluster configuration becomes pivotal to detecting the attack as well as preventing it from happening. There may be a need to showcase compliance with security standards in industries such as healthcare, finance, or government.
Table of Contents
Cluster Architecture
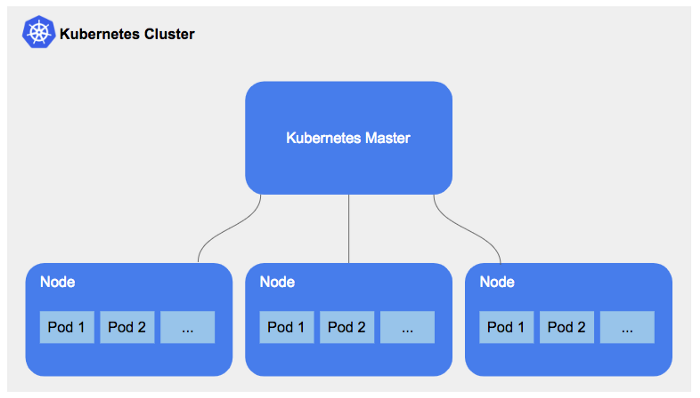
A Kubernetes cluster comprises at least one worker node that hosts the pods (part of the application workload) and is controlled through the control panel. The worker node runs the containerized applications.
Node: It is a worker machine that can be a virtual or physical machine based on the Kubernetes cluster requirement. There are two types of nodes: worker nodes and head nodes.
The fundamental part of the Kubernetes cluster is the head node that is limited to a number usually between 1, 3, or 5. They are responsible for running components such as etcd and the API server.
A worker node is where the cluster’s actual work is done. They run a more limited selection of Kubernetes components where the scheduler works with API servers to schedule containers onto specific worker nodes.
Pod: A pod is a team of one or more containers (such as a Docker container), with a shared storage/neck, and a specification for how to run the containers. Pods share many resources between the containers. The pod shares the same network and interprocess communication namespace to coordinate between the different processes in the pod.
Cluster Management
A cluster being an integral part of Kubernetes requires efficient setup and governing, which can be obtained through the Kubernetes admission controller. It can be considered as the gatekeeper that intercepts (authenticated) API requests and may change the request object or deny the request altogether.
Authentication and admission control are critical for successful deployment and are useful for wrangling user workload. They assist in limiting resource usage, impose security policies, and help enable advanced features. The admission controller can be set by using the below command:
— enable-admission-plugins flag to the kube-apiserver runtime parameters
Handling the Kubernetes cluster operations most efficiently can be achieved by following these guidelines:
Pod Mapping
Based on the resource usage track, plan out the number of pods that will run on each node to avoid the wastage of resources. The container-to-pod and pod-to-node paths can be tracked to improve the configuration and use it effectively.
Node Mapping
Node contribution for the compute and memory resources in the cluster is very crucial. These resource contributions need to be monitored closely to decide the number of nodes required per cluster since larger numbers of lightweight nodes might deliver fewer overall resources as compared to powerful nodes, which are in small numbers. Also in case of failure, a sufficient number of nodes needs to be available to provide backup.
Taints and Tolerations
At the pod level, tolerations can be applied for scheduling them over nodes, which have corresponding taints associated with them. Taints and tolerations together prevent the pod from being assigned to nodes that are not suited to host them since the nodes may be reserved for another workload or user.
Health Monitor
Monitoring the cluster information to track its health is imperative for successful operations. Alerts and dashboards can be developed based on the statistics acquired through cluster scanning to track its health, understand when it is sick, and strategize to bring it back to a healthy state.
Workload Availability
Workload availability means keeping additional nodes available to assist in the case of a worker node failure. These nodes assist the working of the app and minimize the disruption caused. However, if the master node fails, that can be more disruptive and can affect the deployment. Hence, it is critical to build high availability into a Kubernetes cluster and ensure redundancy for master node components.
Networking
This is the principal part of cluster management as the communication between the components is handled here. Developers can define network resources and policies alongside the application deployment manifest. The network strategy is based on the organization’s cloud requirements.
Disaster Recovery Strategy
In the case of a hardware fault on a node, or even data loss in the etcd cluster, there needs to be a system in place to recover in a timely and reliable fashion. Etcd backing should be assigned to three or five nodes. And application data backup depends mainly on how volumes are presented to Kubernetes.
Conclusion
Kubernetes is a potent tool that allows users to aim for high-end application operations. It assists in building, deploying, and managing applications that scale more easily and efficiently. Cluster management thus plays an imperative role in helping developers achieve these complex organizational goals.
I hope you found this article insightful. Thank you for reading!